
Pythonで画像認識してみたいです。
このような要望にお応えします。
今回は、stackGANの学習済みモデルを用いたtext-To-image(文書からの画像生成)をします。
下記のサイトを参考にさせていただきました。
- https://github.com/hanzhanggit/StackGAN
- https://arxiv.org/pdf/1612.03242v1.pdf
- https://www.nogawanogawa.com/entry/stackgan
- http://cedro3.com/ai/pytorch-stackgan/
stackGANの前に
stackGANの前にGANについて整理します。
GANは生成モデルの一種であり、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換することができます。
GANモデルの生成プロセスは、以下の例がわかりやすいと思います。
1.見本のお札を用意する。
2.偽造者のAIがそれを参考に偽札を作成する。
3.警察のAIがそのお札の真贋を判断する。
2, 3を繰り返し、より精巧な偽札を作り出すように生成できるようになる。
このように、GANは2つのネットワークを競わせながら学習させるモデル構造として提案されており、このような構造により、従来モデルより鮮明な画像生成が可能になっています。具体的には、GANはGenerator, Discriminatorと呼ばれる2つのニューラルネットワークで構成され、Generatorは生成データのランダムノイズzに基づき、見本となるデータに近似するように生成します。
Discriminatorは、Generatorが生成した偽物のデータと本物のデータが与えられ、その真偽を判定します。この2つのネットワークを交互に競合させ、学習を進めることで、Generatorは本物のデータに近い偽物データを生成できるようになります。そして、Generatorの生成データと本物のデータの区別ができなくなったときに学習が収束し、Generatorが本物のデータの分布を学習したと判断します。
stackGANについて
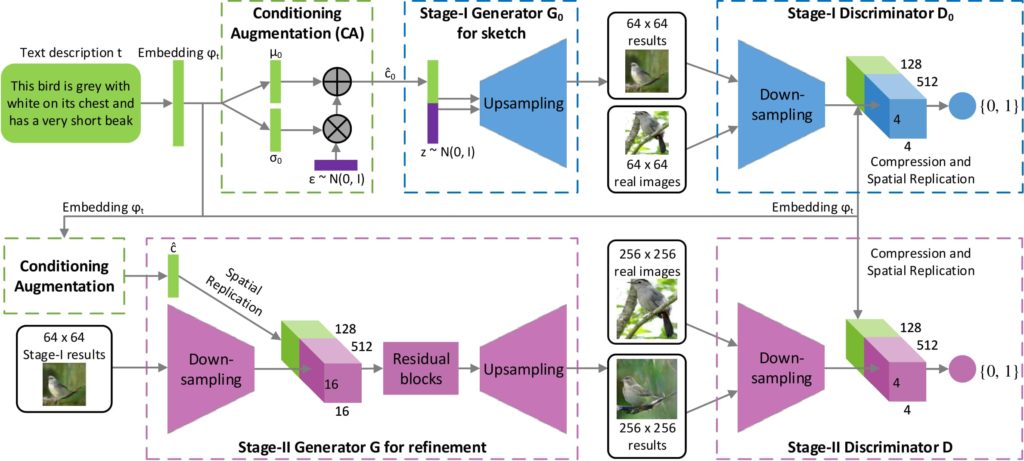
stackGANモデルは、stage-I, stage-IIと呼ばれる2つのGANを用いて画像生成を段階的に行います。GANを多段構成することにより、stage-IのGANで大枠をとらえた低解像度の画像を生成し、stage-IIのGANで高解像度の画像を生成します。
stage-Iでは、画像とそれに対応する説明文書からなるデータセットを学習し、文書から64*64の画像生成を行うモデルを作成します。 ここでは、Generatorは低解像度の画像を生成することを目的としており、Conditioning Augmentationにより変動が加えられた文書の埋め込み表現cと潜在変数zを結合させたベクトルを入力として受け取ります。アップサンプリングして64*64の画像を生成します。
Conditioning Augmentationを使用することで、学習を安定させて生成する画像の多様性を改善しようとしています。埋め込み表現に対して、ガウス分布のノイズを加えることで、同じ画像に対して変動が加えられた埋め込み表現を獲得しようとしています。
stage-IIでは、Generatorは高解像度の画像を生成する、かつstage-Iで生成した低解像度画像の細部を描画することを目的としています。入力は、stage-Iと同様にConditioning Augmentationにより変動を加えた文書の埋め込み表現cとstage-Iで生成した低解像度の画像を使用します。画像を文書に沿う形でアップサンプリングすることで、stage-Iよりも文書情報を鮮明に反映した256*256の画像を生成します。
Discriminatorは、stage-I, stage-IIともに構造的な違いはありません。matching-aware Discriminator(GAN-CLS)を使用しています。このような、GeneratorとDiscriminatorを組み合わせたモデル構造により、説明文書から高解像度の画像データを生成します。
それでは、学習済みstackGANを用いて説明文書から画像を生成してみます。
以下のツールを使用しました。
- https://github.com/hanzhanggit/StackGAN-Pytorch.git
Google Colaboratoryの準備
・Googleのアカウントを作成します。
・Googleドライブにアクセスし、「新規」→「その他」から「Google Colaboratory」の順でクリックします。そうすると、Colaboratoryが起動します。
・Colaboratoryが起動したら、以下のコマンドをCoalboratoryのセルに入力し実行します。
そうすることで、Googleドライブをマウントします。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
・実行後、認証コードの入力が促されます。このとき、「Go to this URL in a browser」が指しているURLにアクセスしgoogleアカウントを選択すると、認証コードが表示されますので、それをコピーしenterを押します。これでGoogleドライブのマウントが完了します。
stackGAN学習済みモデルの準備
Google Colaboratoryの「ランタイム」→「ランタイムのタイプ変更」でGPUを選択します。
ツールをダウンロードする場所に移動します。 本記事では、マイドライブにツールをダウンロードします。
|
1 |
cd drive/My\ Drive |
gitからツールをダウンロードします。
|
1 |
!git clone https://github.com/hanzhanggit/StackGAN-Pytorch.git |
ダウンロードしたフォルダまで移動します。
|
1 |
cd StackGAN-Pytorch/ |
ツール実行に必要なライブラリをインストールします。
|
1 2 3 4 |
!pip2 install torchfile !pip install tensorboard-pytorch !pip uninstall protobuf !pip install --no-binary=protobuf protobuf |
プログラム実行場所に移動します。
|
1 |
cd code |
データセットをダウンロードします。
・https://drive.google.com/file/d/0B3y_msrWZaXLeEs5MTg0RC1fa0U/view
val_captions.t7をStackGAN-pytorch/data/coco/testフォルダの中に格納します。
coco, testフォルダがない場合は、追加してください。
学習済みモデルetG_epoch_90.pthをダウンロードします。
・https://drive.google.com/file/d/0B3y_msrWZaXLYjNra2ZSSmtVQlE/view
netG_epoch_90.pthに名前を変更します。
StackGAN-pytorch/models/cocoに格納します。cocoフォルダがない場合は、作成してください。
以下のコマンドを実行することで説明文書に基づき画像が生成されます。
|
1 |
!python2 main.py --cfg cfg/coco_eval.yml --gpu 0 |
出力結果
a small pizza split into six slices with one missing.



a baseball player is holding a bat and is standing




