データ可視化方法について知りたいです。
このような要望にお応えします。データの可視化は、探索的データ解析において重要な技術の一つですよね。
そこで、今回はデータ解析で重要なプロセスのひとつである探索的データ解析のためのデータの可視化についてPythonライブラリを使用してみます。
探索的データ解析の目的は、良い分析モデルの構築を行うために有効な形にデータを加工することだと考えています。これは、データの特徴や傾向を理解し、目的変数に強く関連する特徴の抽出と不要な特徴の除去を行うことで実現します。
なぜ、このような手順を実施するのかというと、機械学習といったモデルでは、目的変数に関連しない特徴を持つデータをそのまま使用したとき、あまり良いモデルを作ることができないことが多いためです。そのため、目的変数に強く関連する特徴の抽出と不要な特徴の除去を行ったデータを使用することが考えられます。
- データの各要素を理解する。
- それぞれの変数を見て、目的変数に関連するか否かを確認する。
- 単変量に着目した分析
- 特定の一つの変数に焦点を当て、データを理解する。
- 多変量に着目した分析
- ヒートマップを利用して、複数の変数と目的変数との関連を可視化する。これにより、関連性の低いデータを除去する。
- 単変量に着目した分析
- データのクリーニング
- 欠損データや外れ値、カテゴリカル変数を処理します。
Pythonでは、探索的データ解析を支援する様々なライブラリが提供されています。
例えば、以下のようなものがあります。
- pandas・・・データの効率的な使用を支援
- matplotlib・・・データの可視化
- seaborn・・・データの可視化
- numpy・・・テンソル計算を支援
- sklearn・・・機械学習モデルの利用を支援。モデル確認用のデータセットがいくつか用意されている。
実際にライブラリを利用するときには、例えば、以下のようにimportしておきます。
|
1 2 3 4 5 6 |
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np from sklearn.datasets import load_boston %matplotlib inline |
それでは、データを確認してみましょう。今回使用するデータは、sklearnのライブラリに含まれているデータセットを使用してみたいと思います。
今回は、Boston house-prices (ボストン市の住宅価格)のデータを使用します。
- https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
Pythonを用いてデータの構成内容を確認してみます。
本稿では、プログラム実行環境としてjupyter notebookを使用しています。
|
1 2 3 4 5 6 |
import pandas as pd from sklearn.datasets import load_boston bsdata = load_boston() df = pd.DataFrame(bsdata.data, columns=bsdata.feature_names) #データを格納 df['housePrice'] = bsdata.target #目的変数を追加 df |
ここでは、sklearnライブラリにあるデータセットを読み込んで、そのデータをpandasライブラリを用いて格納しています。データセットの読み込み方法や参照方法の詳細ついては、以下が参考になると思いますので確認してみてください。
- https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
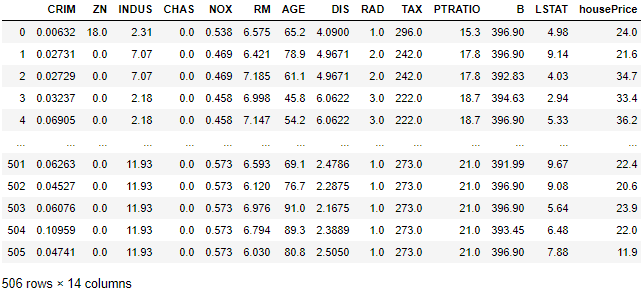
以下のプログラムを実行することで、簡単にデータの構成を確認することもできます。
|
1 |
df.columns |
|
1 2 3 |
Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'housePrice'], dtype='object') |
次に変数間の相関関係を確認してみましょう。
これにより目的変数と関連の高い特徴量を確認することができます。Pythonでは、seabornライブラリを使用することで簡単に変数間の相関関係をグラフ表示させることができます。
例えば、’housePrice’と’CRIM’の関係を図示してみます。
|
1 2 3 4 |
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.jointplot('housePrice', 'CRIM', data=df) |

このように、matplotlibライブラリとseabornライブラリをimportして、seabornライブラリのjointplotメソッドを使用することで変数間の相関関係のグラフを図示することができます。
先程は2変数間の相関関係を確認するのみでしたが、ヒートマップにより複数の変数間の相関関係を確認することができます。
|
1 2 3 4 5 6 7 8 9 10 |
import seaborn as sns import pandas as pd from matplotlib import pyplot as plt %matplotlib inline plt.figure(figsize=(15, 7)) sns.set(style='darkgrid') sns.heatmap(df.corr(), annot=True) plt.ylim(df.corr().shape[0], 0) plt.show() |
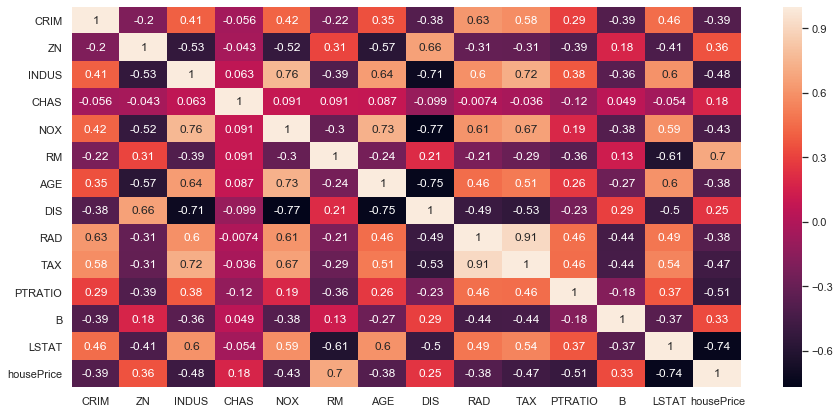
このように、ヒートマップでは、変数間の相関関係が度合いが色で表現されているため、直感的にわかりやすく複数のデータ間の関連が把握しやすいと思います。データセットの特徴量が多い場合に、ヒートマップで全体の関連性を俯瞰し、関連性が高いデータ間の関係をより深堀して確認していくといいかもしれませんね。
以上、探索的データ分析のためのデータ可視化方法について紹介しました。今回扱った内容はあくまで一部だけになりますので、他の方法に興味がある方は、kaggle等のデータ分析コンペを利用してみるのもいいかしれません。

