
Pythonで画像処理してみたいです。
このような要望にお応えします。
以下を参考にさせていただきました。
- https://github.com/anishathalye/neural-style
- Image Style Transfer Using Convolutional Neural Networks( https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf )
今回は、CNN(Convolutional Neural Network)を用いた画像スタイル変換を行います。
コンテンツ画像(入力画像)にスタイル画像を転写することをスタイル変換といいます。
Image Style Transfer(CNNベース)について
画像のスタイル変換の本質は、画像のコンテンツとスタイル表現の分離です。
Gatysさん達は、CNNから得られる特徴空間を利用することで該当の分離を実現しています。
以下、論文からの引用です。
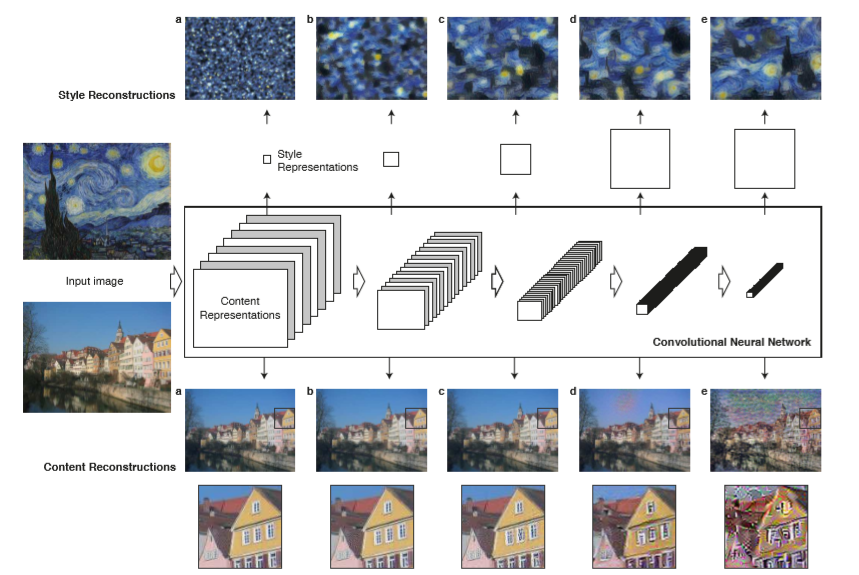
下段の各layerごとの画像を確認すると、これらの画像は各layerにおいてコンテンツ画像を復元したものです。a, b, cまでは元のコンテンツ画像と変わらないように見えますが、d, eではlayerが深くなるに従い詳細な情報が落ちているように見えます。
この図のニューラルモデルは学習済みのVGGを使用しています。このモデルは、画像分類用に学習されたものです。
VGGは、画像分類を行う目的で学習されており、深いlayerであるほど分類に寄与する重要な要素が残り、分類に関係のない情報は排除されると考えられます。これに基づき、画像のコンテンツとスタイルを分離する手法が提案されています。
このように、VGGの中間層の特徴量を使用することでスタイル画像のスタイル表現をコンテンツ画像に転写し、画像のコンテンツ表現を保持しつつ、スタイル表現を変換することができます。
コンテンツ情報を保持し、スタイルを他の画像のスタイル表現に近似するために、コンテンツの損失+スタイルの損失を最小化するような損失関数が定義されています。損失関数の計算の流れとしては、以下のように定義されています。
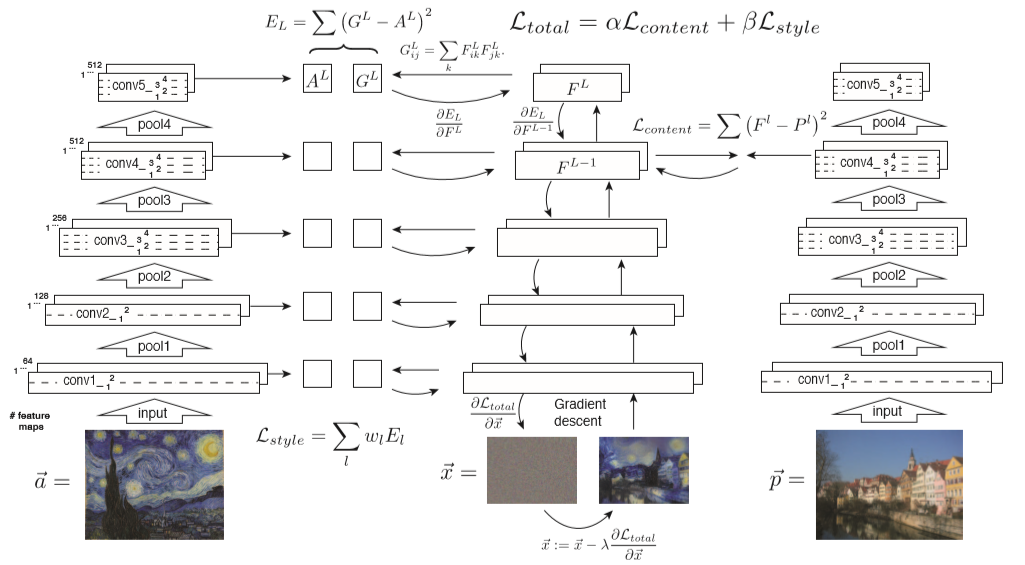
コンテンツの損失は、VGGのconv4_2のlayerの特徴量を用いて、コンテンツ画像と生成画像を比較することにより計算します。
スタイルの損失は、VGGのconv1_1, conv2_1, conv3_1, conv4_1, conv5_1を使用して計算されています。
提案モデルの詳細情報は、論文を参照ください。
- Image Style Transfer Using Convolutional Neural Networks( https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf )
ざっくりと提案モデルのソースコードを確認しました。
モデルとして、VGG19を使用しています。
|
1 2 3 4 5 |
VGG_PATH = 'imagenet-vgg-verydeep-19.mat' parser.add_argument('--network', dest='network', help='path to network parameters (default %(default)s)', metavar='VGG_PATH', default=VGG_PATH) |
画像スタイル変換ネットワークモデル定義は、以下になります。
VGG19の学習済みパラメータを使用しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
VGG19_LAYERS = ( 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2', 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4' ) def net_preloaded(weights, input_image, pooling): net = {} current = input_image for i, name in enumerate(VGG19_LAYERS): kind = name[:4] if kind == 'conv': if isinstance(weights[i][0][0][0][0], np.ndarray): # old format kernels, bias = weights[i][0][0][0][0] else: # new format kernels, bias = weights[i][0][0][2][0] # matconvnet: weights are [width, height, in_channels, out_channels] # tensorflow: weights are [height, width, in_channels, out_channels] kernels = np.transpose(kernels, (1, 0, 2, 3)) bias = bias.reshape(-1) current = _conv_layer(current, kernels, bias) elif kind == 'relu': current = tf.nn.relu(current) elif kind == 'pool': current = _pool_layer(current, pooling) net[name] = current assert len(net) == len(VGG19_LAYERS) return net |
画像スタイル変換は、以下で実施されています。
|
1 2 3 4 |
def stylize(network, initial, initial_noiseblend, content, styles, preserve_colors, iterations, content_weight, content_weight_blend, style_weight, style_layer_weight_exp, style_blend_weights, tv_weight, learning_rate, beta1, beta2, epsilon, pooling, print_iterations=None, checkpoint_iterations=None): |
コンテンツ損失およびスタイル損失などを含めた損失関数は、以下のように計算されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
CONTENT_LAYERS = ('relu4_2', 'relu5_2') STYLE_LAYERS = ('relu1_1', 'relu2_1', 'relu3_1', 'relu4_1', 'relu5_1') style_layers_weights = {} for style_layer in STYLE_LAYERS: style_layers_weights[style_layer] = layer_weight layer_weight *= style_layer_weight_exp # normalize style layer weights layer_weights_sum = 0 for style_layer in STYLE_LAYERS: layer_weights_sum += style_layers_weights[style_layer] for style_layer in STYLE_LAYERS: style_layers_weights[style_layer] /= layer_weights_sum # content loss content_layers_weights = {} content_layers_weights['relu4_2'] = content_weight_blend content_layers_weights['relu5_2'] = 1.0 - content_weight_blend content_loss = 0 content_losses = [] for content_layer in CONTENT_LAYERS: content_losses.append(content_layers_weights[content_layer] * content_weight * (2 * tf.nn.l2_loss( net[content_layer] - content_features[content_layer]) / content_features[content_layer].size)) content_loss += reduce(tf.add, content_losses) # style loss style_loss = 0 for i in range(len(styles)): style_losses = [] for style_layer in STYLE_LAYERS: layer = net[style_layer] _, height, width, number = map(lambda i: i.value, layer.get_shape()) size = height * width * number feats = tf.reshape(layer, (-1, number)) gram = tf.matmul(tf.transpose(feats), feats) / size style_gram = style_features[i][style_layer] style_losses.append(style_layers_weights[style_layer] * 2 * tf.nn.l2_loss(gram - style_gram) / style_gram.size) style_loss += style_weight * style_blend_weights[i] * reduce(tf.add, style_losses) # total variation denoising tv_y_size = _tensor_size(image[:,1:,:,:]) tv_x_size = _tensor_size(image[:,:,1:,:]) tv_loss = tv_weight * 2 * ( (tf.nn.l2_loss(image[:,1:,:,:] - image[:,:shape[1]-1,:,:]) / tv_y_size) + (tf.nn.l2_loss(image[:,:,1:,:] - image[:,:,:shape[2]-1,:]) / tv_x_size)) # total loss loss = content_loss + style_loss + tv_loss |
最適化アルゴリズムはAdamを使用されています。
|
1 2 |
# optimizer setup train_step = tf.train.AdamOptimizer(learning_rate, beta1, beta2, epsilon).minimize(loss) |
それでは、画像のスタイル変換を行います。
Google Colaboratoryの準備
・Googleのアカウントを作成します。
・Googleドライブにアクセスし、「新規」→「その他」から「Google Colaboratory」の順でクリックします。そうすると、Colaboratoryが起動します。
・Colaboratoryが起動したら、以下のコマンドをCoalboratoryのセルに入力し実行します。
そうすることで、Googleドライブをマウントします。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
・実行後、認証コードの入力が促されます。このとき、「Go to this URL in a browser」が指しているURLにアクセスしgoogleアカウントを選択すると、認証コードが表示されますので、それをコピーしenterを押します。これでGoogleドライブのマウントが完了します。
Neural Image Style Transferツールの準備
Google Colaboratoryの「ランタイム」→「ランタイムのタイプ変更」でGPUを選択します。
ツールをダウンロードする場所に移動します。 本記事では、マイドライブにツールをダウンロードします。
|
1 |
cd drive/My\ Drive |
gitからツールをダウンロードします。
|
1 |
!git clone https://github.com/anishathalye/neural-style |
ダウンロードしたフォルダまで移動します。
|
1 |
cd neural-style |
ツール使用時に必要なライブラリをインストールします。
|
1 |
pip install -r requirements.txt |
VGG19の学習済みパラメータをダウンロードします。
|
1 |
!wget http://www.vlfeat.org/matconvnet/models/beta16/imagenet-vgg-verydeep-19.mat |
下記のコマンドを実行することで、コンテンツ画像data.jpgを2-style2.jpgのスタイルに変換することができます。
|
1 2 3 4 5 6 |
!python neural_style.py \ --content examples/data.jpg \ --styles examples/2-style2.jpg \ --output out.jpg \ --iterations 300 \ --overwrite |
出力結果
出力結果は、以下になります。

いかがでしょうか?
コンテンツとスタイル画像の組み合わせを変えてみると多様な結果が得られると思いますので、確認してみてはいかがでしょうか。

