StyleGAN2について
StyleGAN2の前に、GANとStyleGANについて整理します。
GANとは?
GANは生成モデルの一種であり、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換することができます。
GANモデルの生成プロセスは、以下の例がわかりやすいと思います。
1.見本のお札を用意する。
2.偽造者のAIがそれを参考に偽札を作成する。
3.警察のAIがそのお札の真贋を判断する。
2, 3を繰り返し、より精巧な偽札を作り出すように生成できるようになる。
このように、GANは2つのネットワークを競わせながら学習させるモデル構造として提案されており、このような構造により、従来モデルより鮮明な画像生成が可能になっています。具体的には、GANはGenerator, Discriminatorと呼ばれる2つのニューラルネットワークで構成され、Generatorは生成データのランダムノイズzに基づき、見本となるデータに近似するように生成します。
Discriminatorは、Generatorが生成した偽物のデータと本物のデータが与えられ、その真偽を判定します。この2つのネットワークを交互に競合させ、学習を進めることで、Generatorは本物のデータに近い偽物データを生成できるようになります。そして、Generatorの生成データと本物のデータの区別ができなくなったときに学習が収束し、Generatorが本物のデータの分布を学習したと判断します。
StyleGANとは?
StyleGANでは、本物と間違えるほどの高解像度画像を生成することができます。
StyleGANのネットワークでは、Progressive Growingを用いた高解像画像生成、AdaINを用いて各層に画像のStyleを取り込むという2つの特徴があります。
Progresive Growingは、高解像度画像の生成手法の一つです。その特徴は、最初は低解像画像の生成を行い、段階的に高解像画像生成を行うようにGenerator,Discriminatorを追加することにあります。
AdaINは、スタイル変換を実現します。
Xun Huangさん達がこちらの論文Arbitrary Style Transfer in Real-time with Adaptive Instance Normalizationで提案されたスタイル変換のモデルで使用されていますね。提案モデルでは、VGGモデルにより特徴抽出を行い、AdaINを経由してDecoderにより画像のスタイル変換を実現しています。AdaINをモデルに組込んでいる理由は、学習に使用していないスタイル画像を用いてもスタイル変換が可能になるからだそうです。
- https://arxiv.org/pdf/1703.06868.pdf
- https://medium.com/@crosssceneofwindff/adain%E3%82%92%E7%94%A8%E3%81%84%E3%81%9F%E7%94%BB%E9%A2%A8%E5%A4%89%E6%8F%9B-bcfc2dafbce
StyleGANモデルはこのような2つの特徴を持つ構造になっています。
A Style-Based Generator Architecture for Generative Adversarial Networksより、モデル図を引用します。
- https://arxiv.org/pdf/1812.04948.pdf
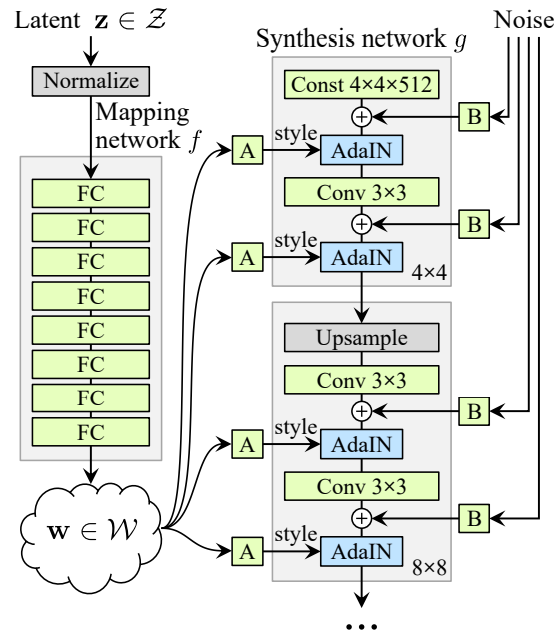
各Generatorで段階的に解像度を上げて画像生成を行います。
モデル図では、4*4から始まり、次に8*8といったように段階的に解像度を上げていき、最終的に1024*1024まで行います。そして、Mapping networkと呼ばれる8層のニューラルネットワークにより出力されたベクトルwを各解像度のAdaINに入力するような形となり、画像生成が行われる構造になっています。
StyleGAN2とは?
本物のような高画質画像を生成することができるStyleGANですが、いくつかの課題がありました。それは、画像中に水滴のようなノイズが発生することです。
この課題に対して改良を行った手法としてStyleGAN2が提案されています。
Analyzing and Improving the Image Quality of StyleGAN
- https://arxiv.org/pdf/1912.04958.pdf
それでは、StyleGAN2を使用して、高画質画像生成をしてみます。
以下を参考にさせていただきました。
- https://github.com/NVlabs/stylegan2
- https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_3_style_gan.ipynb
StyleGAN2の実行環境の準備
Google Colaboratoryの準備
・Googleのアカウントを作成します。
・Googleドライブにアクセスし、「新規」→「その他」から「Google Colaboratory」の順でクリックします。そうすると、Colaboratoryが起動します。
・Colaboratoryが起動したら、以下のコマンドをCoalboratoryのセルに入力し実行します。
そうすることで、Googleドライブをマウントします。
|
1 2 |
from google.colab import drive drive.mount('/content/drive') |
・実行後、認証コードの入力が促されます。このとき、「Go to this URL in a browser」が指しているURLにアクセスしgoogleアカウントを選択すると、認証コードが表示されますので、それをコピーしenterを押します。これでGoogleドライブのマウントが完了します。
StyleGAN2ツールの準備
Google Colaboratoryの「ランタイム」→「ランタイムのタイプ変更」でGPUを選択します。
ツールをダウンロードする場所に移動します。
本記事では、マイドライブにツールをダウンロードします。
|
1 |
cd drive/My\ Drive |
ツールをダウンロードします。
|
1 |
!git clone https://github.com/NVlabs/stylegan2.git |
ダウンロードしたフォルダに移動します。
|
1 |
cd stylegan2/ |
学習済みのモデルパラメータを準備します。まず、modelsフォルダを作成します。
こちら(https://github.com/NVlabs/stylegan2)にある「Using pre-trained networks」で紹介されている「StyleGAN2 Google Drive folder」より、「stylegan2-ffhq-config-f.pkl」をダウンロードし、先ほど作成したmodelsフォルダに保存します。
tensorflowの1.x系を使用します。そして、ツール実行に必要なライブラリをimportします。
|
1 2 3 4 5 6 7 |
%tensorflow_version 1.x import tensorflow import sys sys.path.insert(0, "/content/drive/My\ Drive/stylegan2") import dnnlib |
画像生成処理は、以下になります。ソースコード中のexpand_seed([6900,6920], vector_size)の[6900,6920]を変更することで生成画像を変えることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
# Copyright (c) 2019, NVIDIA Corporation. All rights reserved. # # This work is made available under the Nvidia Source Code License-NC. # To view a copy of this license, visit # https://nvlabs.github.io/stylegan2/license.html import argparse import numpy as np import PIL.Image import dnnlib import dnnlib.tflib as tflib import re import sys import pretrained_networks #---------------------------------------------------------------------------- def expand_seed(seeds, vector_size): result = [] for seed in seeds: rnd = np.random.RandomState(seed) result.append( rnd.randn(1, vector_size) ) return result def generate_images(Gs, seeds, truncation_psi): noise_vars = [var for name, var in Gs.components.synthesis.vars.items() \ if name.startswith('noise')] Gs_kwargs = dnnlib.EasyDict() Gs_kwargs.output_transform = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True) Gs_kwargs.randomize_noise = False if truncation_psi is not None: Gs_kwargs.truncation_psi = truncation_psi for seed_idx, seed in enumerate(seeds): print('Generating image for seed %d/%d ...' % (seed_idx, len(seeds))) rnd = np.random.RandomState() tflib.set_vars({var: rnd.randn(*var.shape.as_list()) for var in noise_vars}) # [height, width] images = Gs.run(seed, None, **Gs_kwargs) # [minibatch, height, width, channel] path = f"/content/drive/My Drive/stylegan2/output/image{seed_idx}.png" PIL.Image.fromarray(images[0], 'RGB').save(path) sc = dnnlib.SubmitConfig() sc.num_gpus = 1 sc.submit_target = dnnlib.SubmitTarget.LOCAL sc.local.do_not_copy_source_files = True sc.run_dir_root = "/content/drive/My Drive/stylegan2" sc.run_desc = 'generate-images' network_pkl = '/content/drive/My Drive/stylegan2/models/stylegan2-ffhq-config-f.pkl' print('Loading networks from "%s"...' % network_pkl) _G, _D, Gs = pretrained_networks.load_networks(network_pkl) vector_size = Gs.input_shape[1:][0] seeds = expand_seed( [6900,6920], vector_size) #generate_images(Gs, seeds,truncation_psi=0.5) print(seeds[0].shape) STEPS = 100 diff = seeds[1] - seeds[0] step = diff / STEPS current = seeds[0].copy() seeds2 = [] for i in range(STEPS): seeds2.append(current) current = current + step generate_images(Gs, seeds2,truncation_psi=0.5) |
以下のプログラムを実行することで、生成した画像をgif形式に変換することができます。
|
1 2 3 4 5 6 7 8 9 10 |
from PIL import Image import glob files = glob.glob('/content/drive/My Drive/stylegan2/output/*.png') images = list(map(lambda file: Image.open(file), files)) images[0].save('/content/drive/My Drive/stylegan2/stylegan2.gif', save_all=True, append_images=images[1:], duration=200, loop=0) |
出力結果






StyleGAN2による本物と間違えるほどの高解像度画像を行いました。プログラム中のseed値を変更することで生成される画像を変化させることができますので試行錯誤してみてはいかがでしょうか。
以下を参考にさせていただきました。
- https://arxiv.org/pdf/1703.06868.pdf
- https://medium.com/@crosssceneofwindff/adain%E3%82%92%E7%94%A8%E3%81%84%E3%81%9F%E7%94%BB%E9%A2%A8%E5%A4%89%E6%8F%9B-bcfc2dafbce
- https://arxiv.org/pdf/1812.04948.pdf
- https://qiita.com/Phoeboooo/items/7be15acb960837adab21
- https://arxiv.org/pdf/1912.04958.pdf
- https://github.com/NVlabs/stylegan2
- https://github.com/jeffheaton/t81_558_deep_learning/blob/master/t81_558_class_07_3_style_gan.ipynb

