
テキストマイニングとは何でしょうか?
このような疑問にお答えします。
テキストマイニングは、大量のテキストデータから、企業もしくは個人に利益をもたらす情報を取り出すことを目的として行います。
自然言語処理の手法を用いて、文書を単語に分割し、各単語の出現頻度、相関関係の分析を通じて有益な情報を抽出します。
自然言語処理(Natural Language Processing:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。(wikipediaより抜粋)
昨今では、通販サイトの口コミ情報や、SNS、ブログ等を代表とするメディア上にも膨大なテキストデータが蓄積されています。
これらのテキストデータは、市場の状況・環境、消費者の製品・サービスに対する人間の感情をリアルアイムに反映しており、これらを積極的に活用することが企業、そして個人ビジネスのアップデートに必要になるのではと思います。
そこで、今回は、テキストマイニングの活用としてpythonを用いてスパムフィルタリングを行ってみます。
データは、【SMS Spam Collection Dataset】を使用します。このデータは、メール文章とその文章が迷惑メールか否かを示す情報の組で構成されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
# テキストデータ前処理用のライブラリの読み込み import pandas as pd import numpy as np import re import nltk from nltk.corpus import stopwords import codecs # データのベクトル化とスパム判定モデル用のライブラリ読み込み from keras.preprocessing.text import one_hot, Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.models import Sequential from keras.layers.core import Activation, Dropout, Dense from keras.layers import Flatten from keras.layers import GlobalMaxPooling1D, Convolution1D, MaxPooling1D from keras.layers.embeddings import Embedding from sklearn.model_selection import train_test_split max_features = 5000 maxlen = 400 batch_size = 32 embedding_dims = 50 nb_filter = 250 filter_length = 3 hidden_dims = 250 epochs = 5 # テキスト前処理定義 def proc_preprocess(raw_text): conv_text = [] # HTML形式のドキュメントのノイズ除去 for sentence in raw_text: # タグ情報除去 sentence = re.compile(r'<[^>]+>').sub('', sentence) # a~z, A~Z以外の要素を除去 sentence = re.sub('[^a-zA-Z]', ' ', sentence) # 1文字だけの要素を削除 sentence = re.sub(r'\s+[a-zA-Z]\s+', ' ', sentence) # 重複するスペース削除 sentence = re.sub(r'\s+', ' ', sentence) conv_text.append(sentence) return conv_text # SMSデータ読み込み with codecs.open("SMSSpamCollection.csv", mode="r", encoding="utf-8", errors="ignore") as file: df = pd.read_table(file, delimiter="\t", header=None) df.column = ['y_data', 'x_data'] df = df.rename(columns={0:'y_data', 1:'x_data'}) df.head(10) |
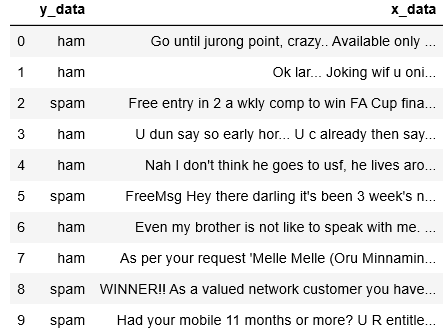
このデータを用いて機械学習できる形に加工します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 学習データ、評価データ準備 x_train = proc_preprocess(df['x_data']) print(x_train[0:2]) # 教師データ数値変換 1:spam,0;ham y_train = df['y_data'] y_train = np.array(list(map(lambda x:1 if x=='spam' else 0, y_train))) # 学習データと評価データに分割 x_train, x_test, y_train, y_test = train_test_split(x_train, y_train, test_size=0.2) tokenizer = Tokenizer(num_words=max_features) tokenizer.fit_on_texts(x_train) x_train = tokenizer.texts_to_sequences(x_train) x_test = tokenizer.texts_to_sequences(x_test) x_train = pad_sequences(x_train, maxlen=maxlen) x_test = pad_sequences(x_test, maxlen=maxlen) |
これでデータの準備ができました。
今回、機械学習のモデルとして、畳み込みニューラルネットワークを使ってみます。モデル定義をしていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 学習モデル定義 def proc_build_model(): model = Sequential() model.add(Embedding(max_features, embedding_dims, input_length=maxlen, dropout=0.2)) model.add(Convolution1D(nb_filter=nb_filter, filter_length=filter_length, border_mode='valid', activation='relu', subsample_length=1)) model.add(MaxPooling1D(pool_length=model.output_shape[1])) model.add(Flatten()) model.add(Dense(hidden_dims)) model.add(Dropout(0.2)) model.add(Activation('relu')) model.add(Dense(1)) model.add(Activation('sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) return model |
これで、畳み込みニューラルネットワークのモデル定義が完成です。実際に学習を実施してみます。
|
1 2 |
model = proc_build_model() model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs) |

学習完了です。次にモデルの評価をしてみます。
|
1 2 |
score = model.evaluate(x_test, y_test, verbose=1) print('score=', score[1], 'loss=', score[0]) |
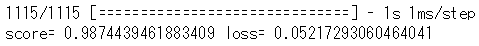
中々良さげな?気もします。どんな感じで分類しているのか確認してみます。
|
1 2 3 |
predict_result = model.predict(x_test[0:10]) print(predict_result) print(y_test[0:10]) |

テストデータの先頭10個のデータを学習したモデルで予測した結果を見ると、一応すべて正解しているみたいです。
最後に、テキストマイニングの分野においても、昨今ではpython等の優れた環境がすでに提供されていますので、企業、個人のビジネスに活用してみましょう。

コメント
[…] pythonによるテキストマイニングことはじめ part.1【プログラムあり】 […]