
テキストマイニングを手軽に試してみたいです。
このような要望にお応えします。
今回は、word2vecを使いたいと思います。
word2vecは、単語をベクトル化する手法のことです。このベクトル化したものを単語の分散表現と呼びます。
自然言語処理分野は多くのベクトル化手法が提案されています。
これらの手法は単語の意味は周囲の単語により形成されるという考えに基づいています。これを分布仮説と呼びます。word2vecも分布仮説に基づいています。
類似する意味や使われ方をする単語は類似する文脈の中に登場するという考えのもと、単語をベクトル化しています。このため、上記のような類似単語動詞はベクトル空間上で近い場所に存在し、コサイン類似度が高くなります。word2vecが登場するまでは、単語の表現方法としてはone-hotベクトルや単語文脈行列をSVD, LSA, LDAなどの次元圧縮手法で圧縮したベクトルが使われていました。最近では、word2vecによる表現がよく使われています。
適用データとしては、特定のキーワードを含むニュース記事をスクレイピングして利用することを考えます。
キーワードは、”暴落”を設定し、ニュース記事を収集しました。
pythonによるスクレイピング時に使われているツールなどは、下記の記事で紹介しています。

収集したデータは、下記のようにcsv形式で保存しています。

対象データにword2vecを適用するソースコードは以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
from janome.tokenizer import Tokenizer from gensim.models import word2vec import pandas as pd def fn_extact_words(text): t = Tokenizer() tokens = t.tokenize(text) return [token.base_form for token in tokens \ if token.part_of_speech.split(',')[0] in ['名詞', '動詞']] def fn_start_word2vec(): keyword = input("filename input-> ") filename = keyword + ".csv" df = pd.read_csv(filename) df.isnull().values.any() df.shape # for sentence in df['summary']: # print(sentence) word_list = [fn_extact_words(sentence) for sentence in df['summary']] # for word in word_list[0]: # print(word) model = word2vec.Word2Vec(word_list, size=100, min_count=5, iter=100) result = model.wv.most_similar(positive=[keyword]) for item in result: print(item[0], item[1]) if __name__ == '__main__': fn_start_word2vec() |
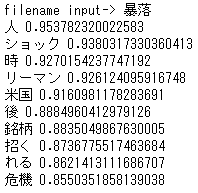
この出力は、キーワード”暴落”に対する関連度が高い単語で構成されているように思います。類義語? or 関連語?ですかね。このように、word2vecを使えば、類義語を見つけることもできます。是非活用してみてください。
