
機械学習手法を用いて画像認識してみたいです。
このような疑問にお答えします。
画像認識は、教師あり学習手法を用いて行います。
教師あり学習については、下記の記事を参照してみてください。

今回は、RandomForestを用いた手書き数字認識を行いたいと思います。
RandomForestは、機械学習モデルのひとつです。
複数の決定木を用いて各決定木の予測結果の多数決で結果を求める方法になります。このように、複数のモデルを用いて性能を向上させる学習方法をアンサンブル学習と呼ばれたりします。RandomForestもアンサンブル学習ということになります。
RandomForestによる手書き数字認識手順
pythonライブラリsklearnを用いることで簡単にRandomForestを使用することができます。
|
1 |
pip install sklearn |
pythonプロンプトを起動し、下記のプログラムが実行できればインストール成功です。
|
1 |
import sklearn |
データは、画像認識のチュートリアルとして頻繁に使用されているMNIST手書き数字認識データセットを使用します。
|
1 2 3 4 5 |
# MNISTデータダウンロード mnist_data = datasets.load_digits() x_train, x_test, y_train, y_test = train_test_split(mnist_data.data, mnist_data.target, test_size=0.2) |
データセットの各画像データは、次元数64(=8×8ピクセル)で構成されています。
そして、0~9までの10クラスがあり、これらのクラスに正しく分類できるように学習を行います。
学習用データの準備から始めます。
画像データを表示してみます。
|
1 2 3 4 5 6 |
# 学習データ表示 plt.figure(figsize=(20, 20)) for index in range(30): plt.subplot(5, 6, index+1) plt.imshow(x_train[index].reshape(8, 8), cmap=plt.get_cmap('gray')) plt.xlabel(y_train[index], fontsize=20) |
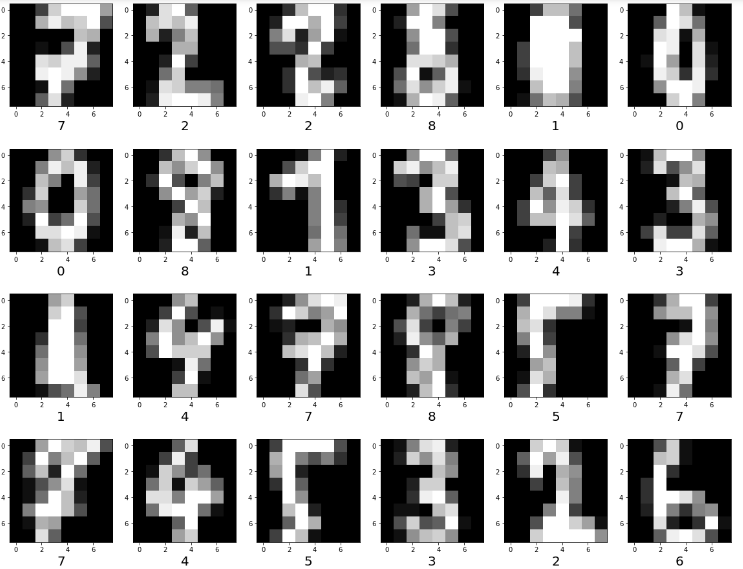
各ピクセル値は、0~255のグレースケールです。そのため、入力値が0~1の範囲となるように正規化を行います。
各値の最大値が255ですので、255除算することにより正規化します。
|
1 2 3 |
# ピクセルデータの正規化 x_train = x_train / 255 x_test = x_test / 255 |
データの準備は、これで完了です。
次に、RandomForestによる学習を行っていきます。
今回の問題は、画像が0~9の整数のうち、どれに相当するのかを学習するマルチクラス分類の問題になります。学習モデルの比較として、ハイパーパラメータチューニングの有無モデルを用いて手書き数字認識をしてみます。
まずは、ハイパーパラメータチューニングなしで行ってみます。
|
1 2 3 4 5 6 |
# randomforest学習 clf = RFC(verbose=True, n_jobs=-1) clf.fit(x_train, y_train) print("acc: ", clf.score(x_test, y_test)) |
acc: 0.9583333333333334
良さげな結果にも見えますね。
学習したモデルを用いた予測結果は以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 予測結果表示 plt.figure(figsize=(20, 20)) for index in range(30): plt.subplot(5, 6, index+1) plt.imshow(x_test[index].reshape(8, 8), cmap=plt.get_cmap('gray')) # 正解の場合は青、不正解の場合は赤 predict_label = predict_result[index] teach_label = y_test[index] if predict_label == teach_label: color = 'blue' else: color = 'red' plt.xlabel("y^->{}, y->{}".format(predict_label, teach_label), color=color, fontsize=20) |

テストデータ画像30枚分を出力してみました。
画像下に出力したラベル色が青の場合、正解データと予測値が一致し、赤色の場合は、
一致しないように出力しています。
結果を見ると、一部赤色になっており、誤分類していることが確認できます。
次に、ハイパーパラメータチューニングありの学習をしてみます。
ハイパーパラメータチューニングは、Grid Searchにて行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# ハイパーパラメータチューニング param = {'n_estimators': np.arange(1, 100)} gs = GridSearchCV(RFC(), param, cv=3, verbose=True, n_jobs=-1) gs.fit(x_train,y_train) print("acc: ", gs.score(x_test, y_test)) predict_result = gs.predict(x_test) # 予測結果表示 plt.figure(figsize=(20, 20)) for index in range(30): plt.subplot(5, 6, index+1) plt.imshow(x_test[index].reshape(8, 8), cmap=plt.get_cmap('gray')) # 正解の場合は青、不正解の場合は赤 predict_label = predict_result[index] teach_label = y_test[index] if predict_label == teach_label: color = 'blue' else: color = 'red' plt.xlabel("y^->{}, y->{}".format(predict_label, teach_label), color=color, fontsize=20) |
acc: 0.9888888888888889
ハイパーパラメータチューニングなしのモデルよりも、良さそうです。
テストデータ画像30枚分を出力してみました。予測結果は、30画像に関して全て正解しているようです。

どうでしょうか?
このようにsklearnを使用すれば、簡単に機械学習モデルを定義、評価、相互比較ができます。
これを機会に様々な教師あり学習手法を試してみてはいかがでしょうか。
