
機械学習のライブラリsklearnというものがあるそうですが、
具体的にどんなことができるのでしょうか?
このような疑問にお答えします。
sklearnは、様々な機械学習手法を簡単に使用することができるツールです。 今回は、sklearnを利用した機械学習入門としてクラスタリングに着眼したいと思います。クラスタリングは、教師なしデータ(ラベル付けがなされていないデータ)に対して、類似属性を持つデータをクラスタと呼ばれる部分集合としてグループ化する手法です。
そして、クラスタリングでは、対象をベクトルとして表現し、コサイン類似度を指標として、データ間の距離(類似度)を計測します。ベクトル表現に変換する際の重み付けの方法については、TF-IDF, BoW等がよく知られています。
例を挙げますと、文書を対象としたクラスタリングを考えたとき、文書に含まれる単語の有無であったり、文書構造の情報を参照し、BoWやTF-IDFに基づきベクトルとして表現し、コサイン類似度を指標として文書間の類似度を測定することができます。
また、クラスタリング分析の結果は、マーケティングに活用できそうなデータとなります。例えば、購買記録を使用して、顧客を分類し、各グループに応じた販売戦略を立てる等に利用できると思います。
- 類似する製品をグループ化
- 類似する店舗をグループ化
- サービス利用傾向が類似する顧客をグループ化
マーケティングに活用できそうな気がしませんか?
ここで、実際にクラスタリング手法として、k-means法を使用してみます。k-means法は、以下の3つの手順を実施することによりクラスタリングを行います。
phase.1 初期値となる重心点をサンプルデータからクラスタ数だけ求める。
phase.2 各サンプルから最も近い距離にあるデータを計算によって求め、クラスタを構成する。
phase.3 phase.2を設定した回数分実行し、類似度に基づきデータを分類する。
クラスタリング分析手順を実装するにあたり、以下のライブラリを使用します。
- pandas
- numpy
- sklearn
- matplotlib
ライブラリがない場合は、pip等を利用してインストールしましょう。
|
1 2 3 4 |
pip install pandas pip install numpy pip install scikit-learn pip install matplotlib |
環境としては、anaconda prompt経由でjupyter notebookを使用します。データは、機械学習の分野では入門用のデータセットとして頻繁に使用されるirisデータを使用します。
|
1 2 3 4 5 6 |
from sklearn import datasets import pandas as pd iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) print(df) |
|
1 2 3 4 5 6 7 8 |
%matplotlib inline import matplotlib.pyplot as plt # 2変数を用いたクラスタリング x = df[['sepal length (cm)', 'petal length (cm)']] print(x.head(10)) # データを平面空間にプロット plt.scatter(x['sepal length (cm)'], x['petal length (cm)'], c='red') plt.show() |
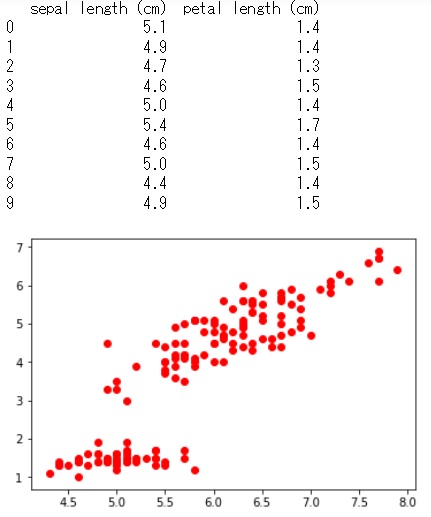
|
1 2 3 4 5 6 |
# クラスタリング from sklearn.cluster import KMeans km = KMeans(n_clusters=3, init='random', max_iter=100, random_state=0) y_res = km.fit_predict(x) print(y_res) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# クラスタリング結果をプロット plt.scatter(x[y_res == 0]['sepal length (cm)'], x[y_res == 0]['petal length (cm)'], c='red', label='cluster0') plt.scatter(x[y_res == 1]['sepal length (cm)'], x[y_res == 1]['petal length (cm)'], c='green', label='cluster1') plt.scatter(x[y_res == 2]['sepal length (cm)'], x[y_res == 2]['petal length (cm)'], c='blue', label='cluster2') plt.grid() plt.legend(loc="upper left") plt.show() |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 正解データがあるので、どの程度正しく分類されているのか傾向を確認 y_label = iris.target.flatten() print(y_label) plt.scatter(x[y_label == 0]['sepal length (cm)'], x[y_label == 0]['petal length (cm)'], c='red', label='setosa') plt.scatter(x[y_label == 1]['sepal length (cm)'], x[y_label == 1]['petal length (cm)'], c='green', label='versicolor') plt.scatter(x[y_label == 2]['sepal length (cm)'], x[y_label == 2]['petal length (cm)'], c='blue', label='virginica') plt.grid() plt.legend(loc="upper left") plt.show() |
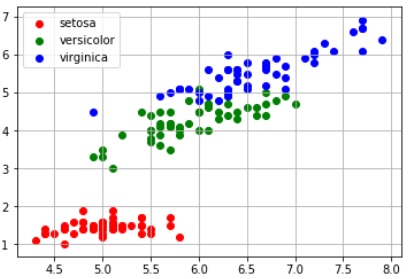

コメント
[…] […]